
Data engineers, software developers, sysadmins. To the untrained eye, we’re all just computer folks.
But to us in the know, we’re far apart when it comes to performing our day jobs, with different challenges and different toolkits. That said, there is one thing that we all tend to know and love: our beautiful terminals. Doing things via command-line instead of dragging your mouse through an interface is the kind of thing that once you get used to, there is no turning back.
And the same applies to Alvin: once you get used to managing and consuming your metadata right from the terminal, well… let’s just say you’ll start asking yourself how you lived without it.
The power of Alvin’s metadata in your terminal? Let’s check out how it works!
Introducing: the Alvin CLI
With the Alvin CLI, you can use all the main features of our tool directly in your favorite terminal:
- Add, remove and modify new platforms;
- Perform impact analysis on your schema changes;
- Support for dbt models;
- Bulk apply (and remove) tags;
- Analyze upstream and downstream column-level data lineage of your assets;
- Add and remove lineage for your assets;
- View usage statistics of your columns, tables and dashboards.
But hey, seeing is believing. So let me show you, in my humble opinion, some of the coolest features for analyzing and managing your metadata in the terminal.
Regression Testing
As I mentioned before: once you get used to the terminal, you never want to leave. And well, we get you.

Whenever you need to drop or change a column or a table, test your SQL and reveal any downstream breaking changes, without leaving your terminal.
Support for dbt models
The regression testing can be used for tables, columns and BI elements. But also for dbt models!
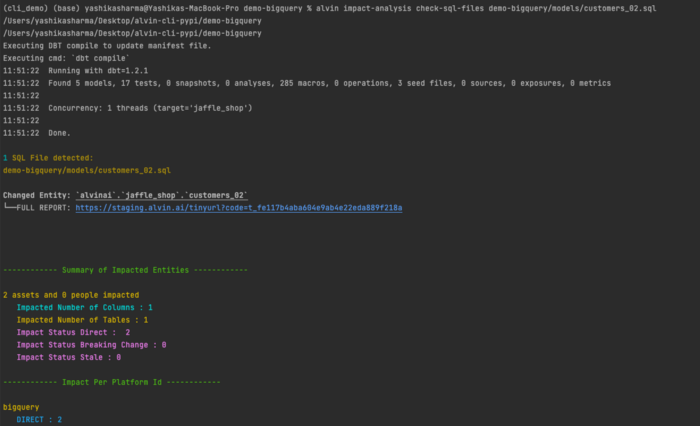
When working with them, you can use the CLI to run tests and get a nice report of what you are going to break (hopefully nothing).
Bulk applying (and removing) tags
Want to apply the same tag to different entities at once? The terminal is your friend. You can apply and delete tags to entities in a batch based on keywords and rules!
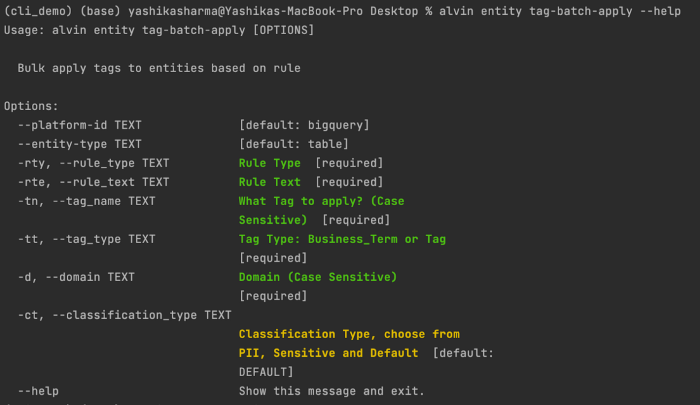
On the Alvin side, we’ll need a few arguments, but based on the input all the matching entities will have the new tag bulk applied to or deleted from them.
Tag batch apply
Let’s say I want to apply a tag to all the column entities from the platform “bigquery” which exactly matches the rule text “first_name”, domain “name”, and the tag I want to bulk apply is “cli_demo” with tag type business_term and classification type “pii” (by default it is “default”).

Once the command executes successfully, you can go to the UI and check out any entity matching the rule and you’ll see the new tag applied to it.
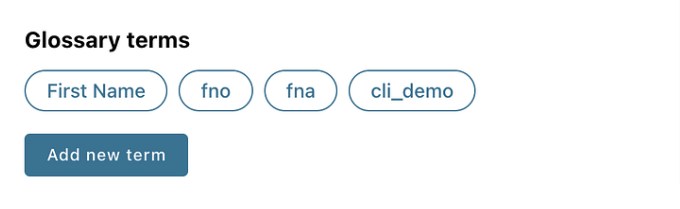
Tag Batch Delete
Similar to applying tags, you can also bulk delete them from entities based on the rule text and other parameters.

You’ll be asked for confirmation before applying the bulk delete operation, but once you confirm, the mentioned tag from all the matching entities gets deleted right away. Pretty neat.

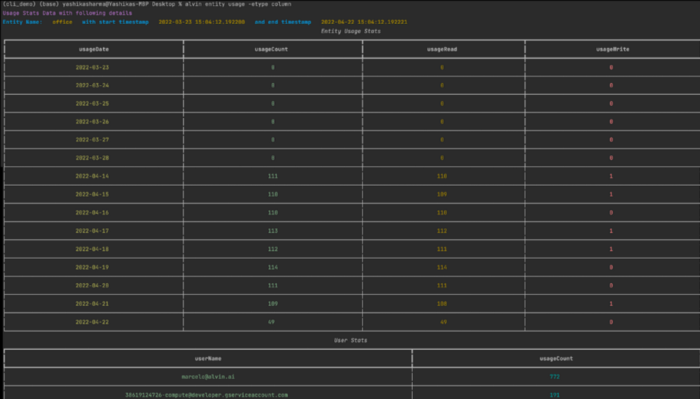
Usage Statistics
Need to know if a specific entity is being used, how many times it was accessed, and by whom? Yeah, you can see that in the CLI too.
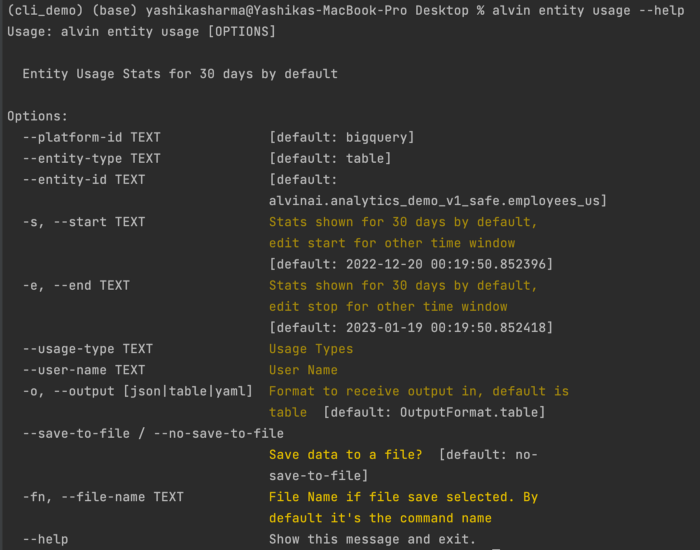
Below is an example of usage statistics from the past 30 days of a column called office. You are also able to see the usage count by user:
Support for tabular, YAML and json formats
Get your data in your preferred format!
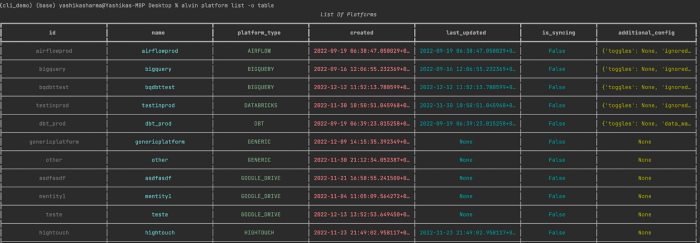
For lovers of the classic tabular format.
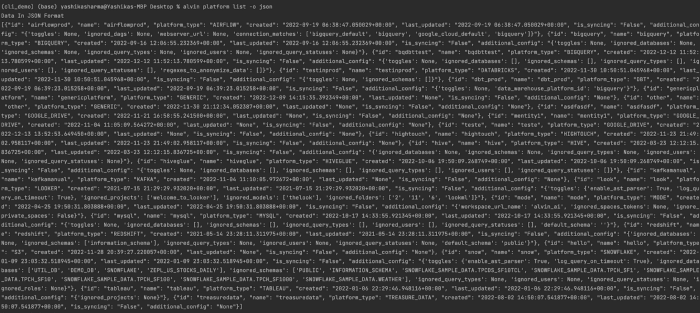
For all of us json lovers out there.
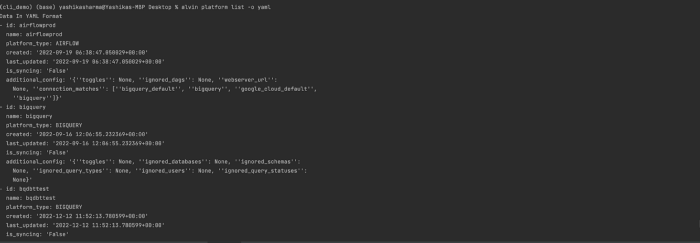
I don’t miss XML at all, but whatever floats your boat.
And you can not only view your data in CSV, JSON and YAML, but also save the output in those formats!
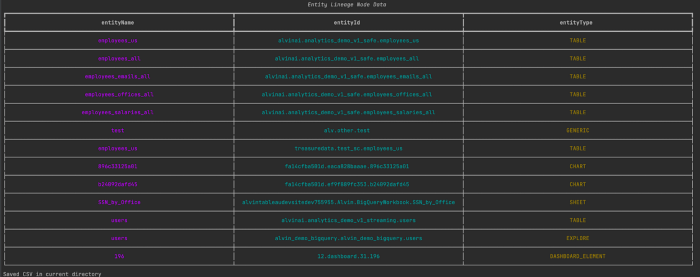
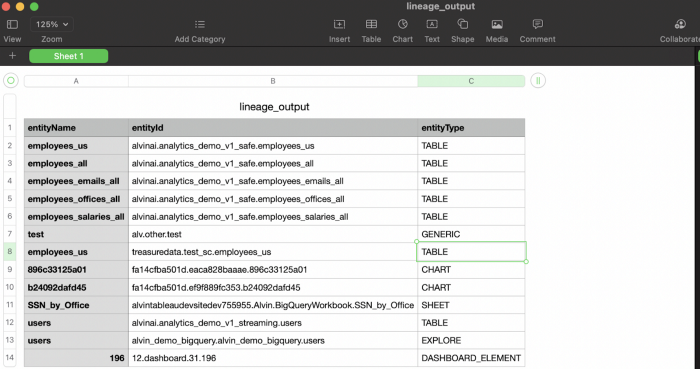
Sample data in tabular format saved in a CSV.

